A few weeks ago I published a piece called "The App Is Dissolving," where I walked through a friction that I think a lot of us who work with AI tools every day have quietly accepted: you bring data to the AI, do the work, and then manually bridge the results back into wherever the rest of your workflow lives. Every session. Both directions. And if you switch tools, you start from zero, because each AI keeps its own memory, its own context, and its own version of what it knows about you and your work.
I described what I thought the answer looked like: an open-source data layer that sits between you and whichever AI you happen to be using, managing your data in a way that is transparent, portable, and genuinely yours. I said I was building toward a release.
This is that release. FlashQuery is live.
What FlashQuery Is
FlashQuery is an open-source data layer for people who use AI as a primary part of how they work. It connects to any AI tool that supports MCP (which, at this point, includes Claude, ChatGPT, Cursor, and a growing list of others), and it manages three types of data that those tools generate but have no good place to put:
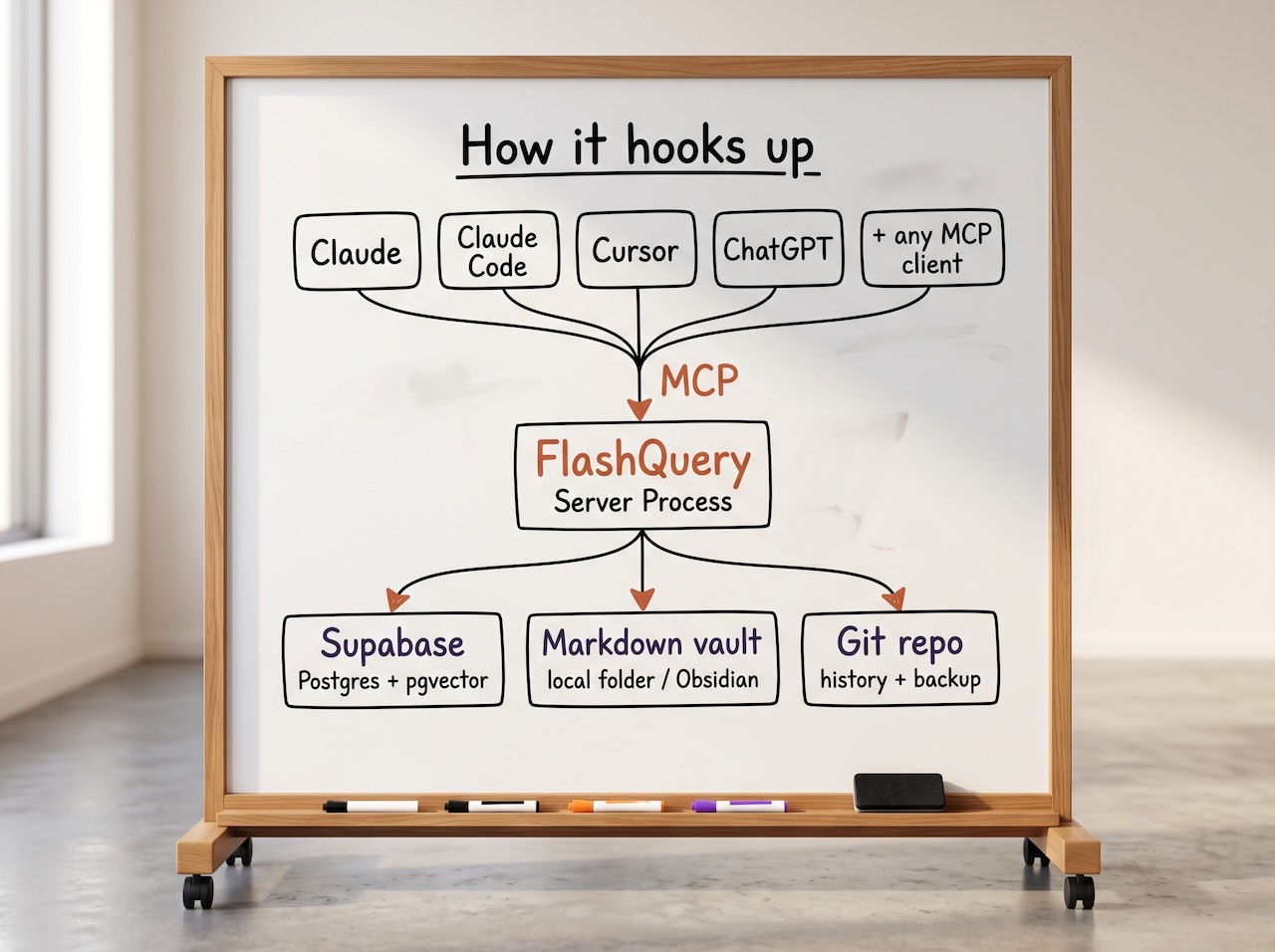
Memory. The preferences, facts, prior decisions, and contextual knowledge that your AI should retain across sessions and across tools. Not locked inside one vendor's memory system; stored in your own database with vector embeddings for semantic search.
Documents. Meeting notes, article drafts, project plans, decision logs. Stored as markdown files in a local folder you point FlashQuery to, organized by project, tagged with consistent metadata. Markdown is the format because it's just text; easily readable as-is, easily rendered for polished viewing, and completely portable. There's no proprietary layer between you and your information.
Structured records. Contacts, interactions, pipeline data, relational information that benefits from proper database queries. Stored in Postgres via Supabase, where you can see and query everything directly.
These three data types are managed together, with a unified taxonomy that keeps tags, project associations, and metadata consistent across all of them. A search for "everything tagged #website-redesign" returns results across memory, documents, and records in one coherent set, because the data layer treats them as one system even though they live in different stores underneath.
Why This Needs to Exist
There's been genuinely good work in this space. Mem0 has built a sophisticated memory layer with real enterprise traction. Open Brain showed that a simple Supabase table behind an MCP server can spark an entire community in weeks. Letta has pushed the boundaries of what stateful agent memory can look like.
And it's worth noting that this recognition isn't limited to the open source community. Andrej Karpathy recently published a compelling sketch of what he calls an "LLM Wiki": a persistent, LLM-maintained knowledge architecture where information accumulates over time rather than being rediscovered from scratch on every query. His core observation, that the tedious part of maintaining a knowledge base isn't the reading or the thinking but the bookkeeping, and that LLMs can handle that bookkeeping at near-zero cost, is one that I think a lot of people working seriously with AI have arrived at independently. Smart people are converging on the same insight from different directions, which tends to be a signal that the insight is sound.
What I kept running into, though, is that each of these efforts addresses a subset of the problem. Memory is one data type, and an important one, but it isn't the whole picture. When I'm working with AI across a typical day, the outputs aren't just memories; they're documents, relational records, project artifacts, contact information, interaction histories. A memory-only solution handles one slice. The rest of it ends up scattered across chat threads, local files, and whatever ad hoc organization I can manage between sessions.
FlashQuery's thesis is that you need the full stack: memory, documents, and structured data, all managed in one layer, all accessible to any AI you use, and all stored in formats that you own and can inspect, edit, and take with you.
What It's Built On
I want to be straightforward about the technical choices, because I think they matter for trust. FlashQuery is built on infrastructure that already has deep community trust and proven track records:
Supabase and Postgres handle relational data, vector storage, and semantic search via pgvector. Your data lives in a Postgres instance you control, and you can see everything through the Supabase dashboard.
Markdown files in a local folder handle documents. You point FlashQuery at any directory you like, and that becomes your vault. The files are organized by project with full frontmatter metadata. If you happen to use Obsidian, the vault works there natively, but there's no dependency on it; any text editor, any file browser, any tool that reads markdown will work just as well.
Git handles versioning and backup, if you want it. If your vault folder is a Git repository, FlashQuery commits every change with a meaningful commit message, and your entire data layer (documents and database dumps together) backs up to a single private repo. If it's not a Git repo, FlashQuery gracefully skips the versioning and everything else works the same.
MCP is the connectivity layer. FlashQuery runs as an MCP server, so any AI tool that speaks MCP can read from and write to it. You don't configure integrations per tool; you connect once and every AI has access to the same data.
The point of these choices is that none of them are exotic. If you're the kind of person who's reading this article, you've almost certainly used most of these tools already. And if you ever decide to stop using FlashQuery, your data is still right there: markdown files you can open in any editor, a Postgres database you can query directly, and a Git repo you can clone. Nothing proprietary. Nothing hidden.
Your Context Should Be Yours to Manage
I want to be precise about the privacy angle here, because it's easy to overstate what any tool in this space can do. If you're using a commercial language model, your prompts and conversations are going to that vendor's infrastructure. That's how the technology works, and FlashQuery doesn't change it.
What FlashQuery does address is a different but related problem: the information that flows through those interactions, the memories, the documents, the decisions, the relationships, tends to either evaporate when the conversation ends or get captured inside vendor-controlled memory systems that you can barely see, let alone organize. We've been through a version of this before. Over the past decade and a half, we collectively handed over enormous amounts of personal information to social media platforms, often without fully appreciating what we were giving up. I'd argue the data flowing through AI workflows is more personal and more valuable than anything we ever posted on a social network, because it includes our thinking patterns, our decision-making context, our professional knowledge.
FlashQuery takes the position that you should be able to capture and manage your own context as you use these tools. It lives on your machine, in your database, in your files. You decide what gets stored, you can see and edit everything that has been captured, and the information is organized in a way that you control. And if you ever decide to move to self-hosted language models, your entire context layer is already organized and ready to go; it's plug-and-play at that point, because the data was never locked inside a vendor's ecosystem.
Simplicity as a Design Principle
When I say "data infrastructure layer," I realize that sounds like something that requires a weekend of configuration and a DevOps background to set up. I want to push back on that assumption, because simplicity of use has been a core design premise from the start.
In practice, using FlashQuery means two things: you talk to your AI (whichever one you prefer), and you can open your files in any file browser or text editor whenever you want to see what's been captured. FlashQuery handles the routing, the embedding, the taxonomy, the versioning, the synchronization, and the database operations underneath. That last part matters: you can interact with your file system the way you normally do, make edits directly in your files, and FlashQuery keeps everything in sync between the file layer and the database layer. You don't need to choose between using the AI interface and using your normal tools; you use both, and FlashQuery handles the coordination under the hood. It's the kind of infrastructure that's almost invisible when it's working well, the sort of thing nobody enjoys building but everyone appreciates having, until it isn't there.
Plugins: Building on Top
One of the things I'm most interested in exploring is what happens when FlashQuery becomes a platform rather than just a data store. The plugin system lets you define new schema, new tools, and new data structures that extend what FlashQuery can manage.
Concretely, a plugin is composed of Claude Skills (which define the AI-facing behaviors and instructions) and a schema written in YAML (which declares how the data should be organized in the database). YAML is approachable by design; it's a straightforward way to declare the structure of your information without needing to write SQL or manage migrations yourself. If you're using Claude, you can effectively build new capabilities from the AI interface itself, and FlashQuery becomes the data store underneath. We even have a skill that creates FlashQuery-enabled skills and plugins, which, yes, is exactly as meta as it sounds.
The example I keep coming back to (because I built it and use it daily) is a CRM plugin. You install a single plugin file, and your AI suddenly has a full CRM: contacts, interactions, opportunities, pipeline queries. No application. No login screen. No SaaS subscription. Just data and AI. I described this in "The App Is Dissolving" as a concept, and the announcement I'm making today is that it works. I've been using it to manage real relationships, and the friction reduction compared to maintaining a traditional CRM alongside my AI workflows is significant. I can shut off my paid CRM SaaS now.
What makes the plugin model interesting is composability. Install a second plugin alongside the CRM (a product knowledge tracker, for instance), and the two share a data layer without any integration between them. A query that spans your contacts and your product backlog isn't a cross-system integration effort; it's a semantic search. The multi-billion dollar integration industry (Zapier, MuleSoft, Boomi) exists because applications traditionally couldn't share data without someone building a bridge. When the data lives in one managed layer, that problem dissolves along with the app.
Who This Is For
I want to be honest about scope. FlashQuery is built for individuals and small teams who work with AI tools seriously and feel the pain of fragmented data across those tools. If you use two or more AI tools regularly and you've ever wished they shared context, or you've lost important information when a conversation closed, or you've spent time manually organizing outputs that the AI could have managed for you, this is designed to solve that.
This is not (today) an enterprise platform. There is an enterprise product in the FlashQuery family (FlashQuery Enterprise) that addresses multi-tenancy, governance, identity, and policy enforcement for organizations. The open-source project is the personal counterpart: same philosophy around data ownership and vendor independence, built for the individual user who wants their AI workflows to actually accumulate knowledge over time instead of starting from zero every session.
Try It
The repo is live on GitHub. The setup is designed to be approachable: clone, install, run the interactive setup, and connect your AI. There's a bundled Docker stack if you want everything local, or you can point it at a Supabase Cloud instance if you prefer.
If you're interested in where this is headed, or if you want to build something on top of it (plugins, integrations, workflows I haven't thought of), I'd genuinely like to hear from you. The FlashQuery Open Source page has everything you need to get started, and we have an active community in the AI Product Hive Slack where I'm reachable and responsive.
And if you think I'm solving the wrong problem, or solving the right problem the wrong way, I'd like to hear that too. This is early, the architecture is sound but the ecosystem is nascent, and the people who show up now are the ones who shape what it becomes.
You can reach me here.
