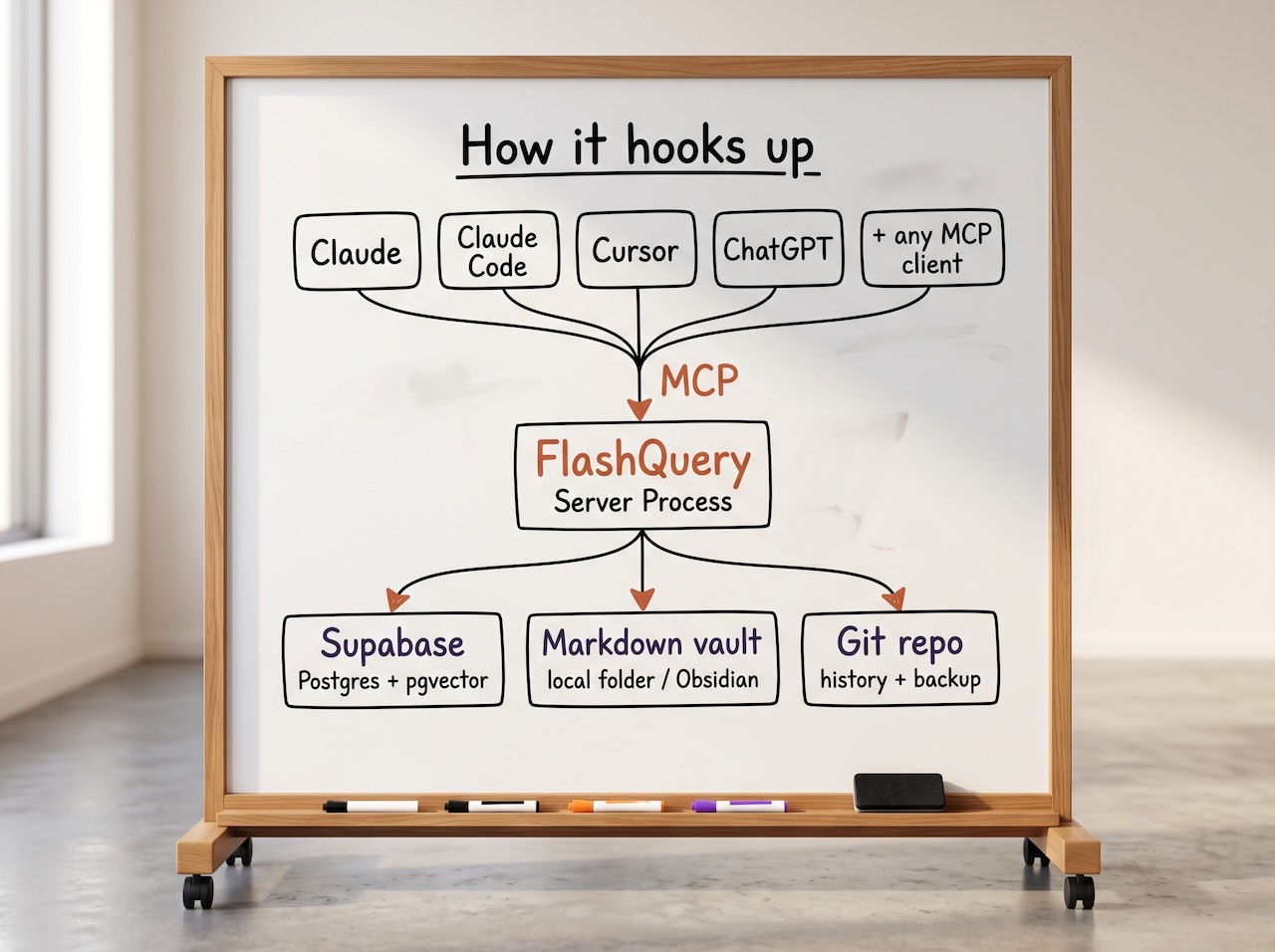
MCP data layer for shared access to memory + documents + structured data
Local, Open Source, backed by Supabase and Git.
One store. Every MCP-compatible AI tool reads and writes to it. Switch tools; the context stays.
Early release Architecture is solid, community is just getting started.
git clone https://github.com/FlashQuery/flashquery